





I. Introduction▲
Le sujet de ce mémento peut vous surprendre, car le problème du voyageur de commerce (traveling salesman problem) ne se rencontre pas souvent dans les forums de programmation en VBA.
Pour ceux qui n'en ont jamais entendu parler, je rappelle ici la présentation qu'en fait Wikipédia :
« Étant donné n points (des "villes") et les distances séparant chaque point, trouver un chemin de longueur totale minimale qui passe exactement une fois par chaque point et revienne au point de départ ».
Dit autrement, un voyageur de commerce doit optimiser sa tournée, sans passer deux fois dans la même ville.
Le plus simple est de tester tous les chemins possibles. Par exemple, si notre voyageur part de la ville A et doit visiter trois villes, BCD, avant de rentrer chez lui, il faut tester ABCDA, ABDCA, ACBDA, ACDBA, ADBCA, ADCBA. Soit (1x2x3) = 6 combinaisons. Le tout peut être divisé par deux, car les chemins parcourus dans un sens ou l'autre sont identiques. ABCDA est égal à ADCBA. Soit trois combinaisons à tester. Facile et rapide.
Seulement, le nombre de combinaisons explose avec le nombre de villes à visiter. D'après la formule (n!/2), avec dix villes (n=10) il y a déjà 1 814 400 combinaisons (1x2x3x4…x10)/2, et avec vingt villes il y en a 1,2x1018, soit un temps de calcul estimé à plusieurs milliers d'années.
Avec un algorithme basique qui explore toutes les combinaisons, il est donc impossible de trouver la solution si 250 villes doivent être visitées… Sauf que des méthodes plus sophistiquées ont été développées par des mathématiciens et des informaticiens pour optimiser les calculs, de telle sorte que, aujourd'hui, « des algorithmes existent et donnent de bons résultats dans des temps raisonnables ».
Ces algorithmes (écrits en C ou autres langages réservés aux scientifiques) faisant appel à des mathématiques qui me dépassent, je vais me contenter dans ce mémento de présenter une méthode d'approximation qui reprend des principes simples, à la portée de tous, rien de très original donc et qui ne permet pas de rivaliser avec les meilleurs, mais qui donne une combinaison cohérente et pas ridicule…
Ce qui pourrait peut-être vous suffire dans vos applications.
Par exemple pour planifier la tournée d'un livreur.
Vous trouverez le code source dans le fichier EXCEL joint. À défaut d'être parfait, cet algorithme permet en tout cas d'avoir un code en VBA, ce qui n'est pas facile à glaner sur Internet.
Mais avant d'examiner l'appel à la fonction PVDC, qui retourne la meilleure combinaison trouvée, je vais vous présenter ces fameux principes si simples qu'ils semblent évidents.
Cette étude vous permettra de mieux comprendre les paramètres utilisés, que vous devrez peut-être configurer pour adapter la fonction à vos besoins.
II. Le Tour de France en 45 villes▲
Pour présenter les principes utilisés par la méthode d'approximation que je vous propose, nous allons étudier une carte de France constituée de 45 villes (points) à visiter.
Vous pouvez l'imprimer et essayer, à la main, de trouver le chemin optimal, vous le comparerez plus tard avec la solution calculée par l'algorithme.
Pour cet exemple purement théorique, les trajets sont effectués « à vol d'oiseau », ne tenez pas compte pour le moment des contraintes liées aux distances réelles, ni aux obstacles géographiques.
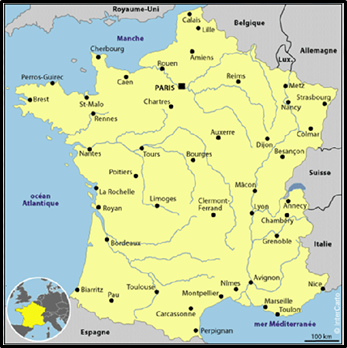
45 villes, mais par où commencer ?
J'ai retenu la solution la plus rationnelle : en sélectionnant les quatre points cardinaux. Puisqu'en principe le chemin optimal devrait passer par ces points et dans cet ordre :
|
|
Le parcours de base est constitué de quatre points avec un retour à l'origine : Perpignan, Brest, Calais, Strasbourg, Perpignan. |
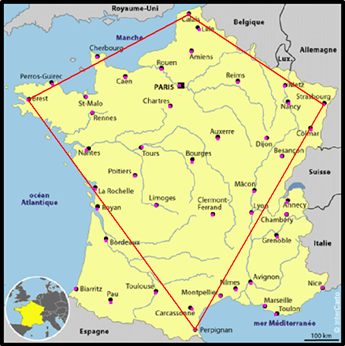
Puis j'analyse chaque point restant en calculant la distance du parcours si j'ajoute ce point entre Perpignan et Brest, entre Brest et Calais, entre Calais et Strasbourg, entre Strasbourg et Perpignan.
Et je vais retenir celui qui va augmenter le moins la distance du parcours.
Cette technique est appelée « l'insertion de moindre coût ».
Je vous rappelle la formule de calcul de la distance entre deux points que vous avez apprise au collège.
Distance entre A et B = racine carrée de ((ordonnée de A - ordonnée de B) au carré) + (abscisse de A - abscisse de B) au carré).
|
|
Après analyse des 41 points restants, un passage par La Rochelle entre Perpignan et Brest est la solution qui augmente le moins la distance du parcours. |
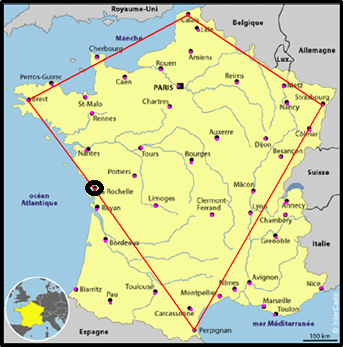
Je répète l'opération sur les 40 points restants en incluant à l'analyse le point retenu, La Rochelle.
|
|
Passer par Colmar entre Strasbourg et Perpignan est la solution qui permet de minimiser le parcours en ajoutant une ville. |
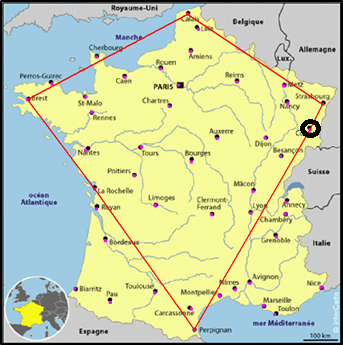
À la fin du traitement de tous les points, j'obtiens un résultat qui, visuellement, est cohérent.
|
|
Pourtant en regardant de près, on devine qu'il y a un chemin plus court que Rennes, Brest, Perros-Guirec, Saint-Malo, Cherbourg. Nous avons l'intuition que ce tracé peut être amélioré. Comment ? Il faut analyser les différentes combinaisons des trois villes entre Rennes et Cherbourg : soit six combinaisons comme nous l'avons vu dans l'introduction, et non divisible par deux, car nous devons suivre un sens non réciproque. |

L'optimisation de Rennes - Brest - Perros-Guirec - Saint-Malo - Cherbourg peut être représentée par l'analyse de la combinaison A - BCD - E. Comme A et E restent fixes, cela représente six différentes combinaisons possibles pour BCD. Et retenir la combinaison de la plus faible distance.
|
|
Le nombre de villes analysées (ou niveau d'analyse) comprises entre la ville de départ et la ville d'arrivée détermine la durée du traitement : |
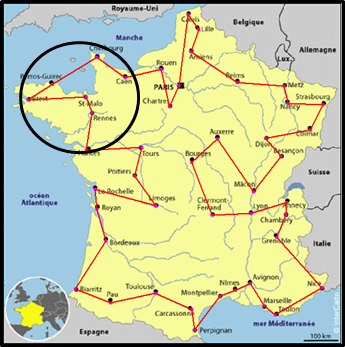
Remarque : vous pouvez choisir un niveau d'analyse supérieur au besoin, ça marche quand même. Ici avec un niveau 8 le résultat aurait été identique qu'avec un niveau 3. Plus le niveau est élevé, plus vous serez capable de trouver des chemins plus courts sur des nœuds complexes, mais en contrepartie, les temps de traitement augmentent.
Les spécialistes parlent de « méthode naïve » pour décrire cette technique d'amélioration qui teste toutes les combinaisons possibles.
À la fin du traitement d'amélioration des 45 points, nous obtenons cette carte :
|
|
Une partie de parcours doit attirer votre attention. Voir le cercle ci-contre. Pourquoi de La Rochelle, passer par Limoges, Poitiers, Tours, puis rejoindre Nantes. Il est plus court de passer de La Rochelle à Nantes, et intégrer Tours, Poitiers, Limoges, au cycle Bourges, Clermont-Ferrand. |
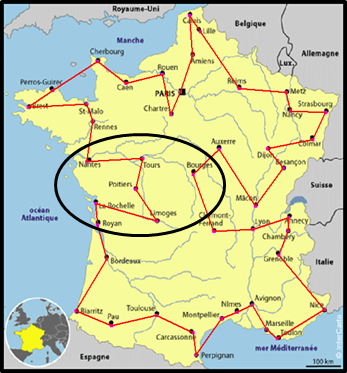
Pour réaliser cette amélioration, il faut boucler sur les points du parcours. Pour chaque point, supprimer les trois prochains points pour se raccorder directement au quatrième, et raccrocher ces trois points plus loin dans le parcours. Emplacement qui sera décalé d'un point à chaque tentative, jusqu'à la fin du parcours.
|
|
À partir de La Rochelle, les trois points suivants, Limoges, Poitiers, Tours, sont supprimés du parcours et raccrochés entre Nantes et Rennes, puis entre Rennes et Saint-Malo, puis entre Saint-Malo et Brest… et ainsi de suite jusqu'à Montpellier, Perpignan. À chaque fois la distance du parcours est calculée.Finalement, on retient la meilleure amélioration faite, encadrée ci-contre. En pratique le décalage commence au premier point du cycle au lieu de commencer à Nantes. |
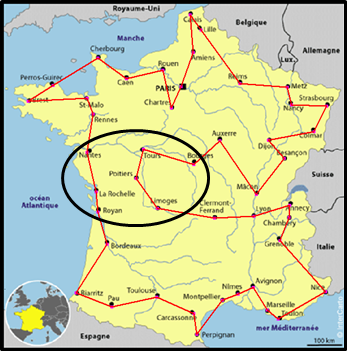
Attention : le niveau d'amélioration choisi doit correspondre au besoin. Ici un niveau 4 n'aurait pas marché. Il faut donc faire une boucle et décrémenter le niveau choisi jusqu'à 1 pour arriver au résultat.
Cette méthode d'amélioration est appelée « déplacement d'arêtes ».
À la fin de ce traitement d'amélioration des 45 points, nous obtenons cette carte :
|
|
Vous pouvez comparer ce tracé avec celui que vous avez fait à la main, pour vérifier votre intuition. |
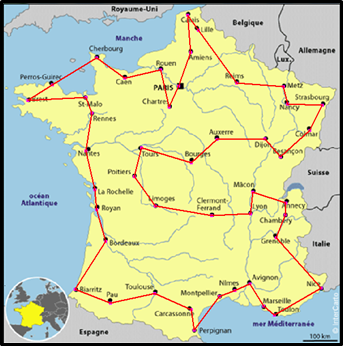
Avec des niveaux d'analyse de 7 aux deux traitements décrits ci-avant, ce tracé a été obtenu en moins d'une seconde sur un PC à 3,4 GHz.
Notez que j'ai utilisé une astuce sur ces améliorations : chaque fois qu'un meilleur parcours est trouvé, le traitement est relancé. Normal, puisqu'une modification peut générer une amélioration qui n'était pas possible avant.
De même, si le deuxième traitement d'amélioration trouve un parcours plus court, il faut relancer le premier traitement d'amélioration qui pourra peut-être faire encore mieux.
Et cela tant que des modifications du parcours sont faites.
Ce qui implique de refaire les calculs d'amélioration par la méthode naïve sur des portions déjà analysées. Pour éviter de perdre du temps, il est préférable de mémoriser les résultats obtenus et de les appliquer en cas d'appel identique, au lieu de relancer les calculs.
Il existe d'autres méthodes d'améliorations. La plus connue et la plus simple à mettre en œuvre est l'amélioration dite « 2-opt ».
III. L'amélioration 2-opt▲
Difficile de parler d'optimisation d'un cycle sans parler de l'amélioration « 2-opt » de Georges A. Croes. Ce célèbre algorithme (voir https://fr.wikipedia.org/wiki/2-opt) « consiste à parcourir le cycle à la recherche de deux arêtes (A, B) et (C, D) qui peuvent être remplacées par (A, C) et (B, D) et réduisent ainsi la distance du parcours ».
Vous comprendrez mieux avec ce graphique extrait de Wikipédia :
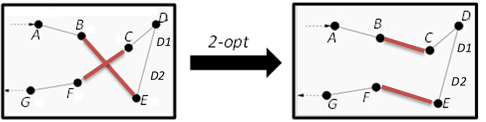
Dans le tracé A-B-E-D-C-F-G, la distance de (B, E) + (C, F) est supérieure à (B, C) + (E, F) donc le tracé devient (B, C) à la place de (B, E) et (E, F) à la place de (C, F) : Ainsi, A-B-E-D-C-F-G devient A-B-C-D-E-F-G.
Attention, il est parfois nécessaire d'inverser l'ordre des points entre la partie permutée. Par exemple, si en plus de D nous avions les points D1 et D2 alors le tracé A-B-E-D2-D1-D-C-F-G devient A-B-C-D-D1-D2-E-F-G.
2.
3.
4.
5.
6.
7.
8.
Fonction 2-opt.
Pour i = 1 jusqu'à nombre de points - 1
Pour j = 1 jusqu'à nombre de points - 1
Si j < i - 1 et j > i + 1 alors
Si distance(i, i+1) + distance(j, j+1) > distance(i, j) + distance(i+1, j+1) alors
Remplacer les arêtes (i, i+1) et (j, j+1) par (i, j) et (i+1, j+1)
Inverser l'ordre des points entre i+2 et j-1
Recommencer tant que des permutations sont faites.
Pour un traitement deux fois plus rapide, l'analyse d'une arête peut porter uniquement sur les points en aval de cette arête, et pas sur tout le cycle :
2.
3.
4.
5.
6.
7.
Fonction 2-opt-LPA (limitée aux points en aval).
Pour i = 1 jusqu'à nombre de points - 4
Pour j = i + 2 jusqu'à nombre de points - 2
Si distance(i, i+1) + distance(j, j+1) > distance(i, j) + distance(i+1, j+1) alors
Remplacer les arêtes (i, i+1) et (j, j+1) par (i, j) et (i+1, j+1)
Inverser l'ordre des points entre i+2 et j-1
Recommencer tant que des permutations sont faites.
Cette méthode permet, aussi, de supprimer les croisements, nous l'utiliserons parfois dans ce but.
IV. L'amélioration 3-opt▲
L'amélioration « 3-opt » est une variante de l'amélioration « 2-opt », qui tente de remplacer trois arêtes et non plus deux. Cette amélioration est donc plus efficace que « 2-opt », mais les temps de traitement risquent d'exploser. Avec 100 points, « 2-opt » limitée aux points en aval demande 4.656 tests, où « 3-opt » limitée aux points en aval en demande 142.880. Et 714.684 sans limiter aux points en aval.
2.
3.
4.
5.
6.
7.
8.
Fonction 3-opt-LPA (limitée aux points en aval).
Pour i = 1 jusqu'à nombre de points - 6
Pour j = i + 2 jusqu'à nombre de points - 4
Pour k = j + 2 jusqu'à nombre de points - 2
Si distance(i, i+1) + distance(j, j+1) + distance(k, k+1) > distance(i, j) + distance(i+1, k) + distance(j+1, k+1) alors
Remplacer les arêtes (i, i+1) et (j, j+1) et (k, k+1) par (i, j) et (i+1, k) et (j+1, k+1)
Inverser l'ordre des points entre i+2 et j-1 et entre j+2 et k-1
Recommencer tant que des permutations sont faites.
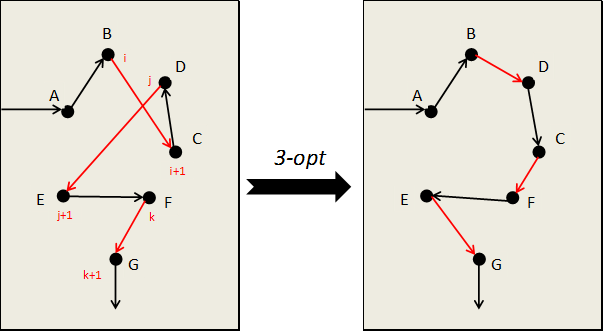
Sur le même principe, vous pouvez développer une amélioration « k-opt » où k représente le nombre d'arêtes à remplacer dans le cycle.
Il semble que les meilleures techniques de résolution utilisent une valeur de k importante.
V. L'amélioration Lin-Kernighan▲
En cherchant sur Internet des algorithmes pour le problème du voyageur de commerce, j'ai souvent rencontré des documentations qui consacraient un chapitre à faire l'éloge de l'excellent algorithme de Shen Lin et Brian Kernighan, mais sans jamais en donner une explication claire et détaillée.
Certains auteurs se contentent même de déclarer qu'il est trop complexe pour être décrit dans leur ouvrage. Alors je me suis inspiré du rapport de Keld Helsgaun, « An Effective Implementation of the Lin-Kernighan Traveling Salesman Heuristic » pour écrire, à ma sauce, un algorithme très simplifié avec le peu que j'ai réussi à comprendre.
L'algorithme se base sur le principe des améliorations « 2-opt » et « 3-opt », en limitant la recherche des arêtes à échanger aux plus proches voisins du dernier point de l'arête testée.
Reprenons le graphique précédent :
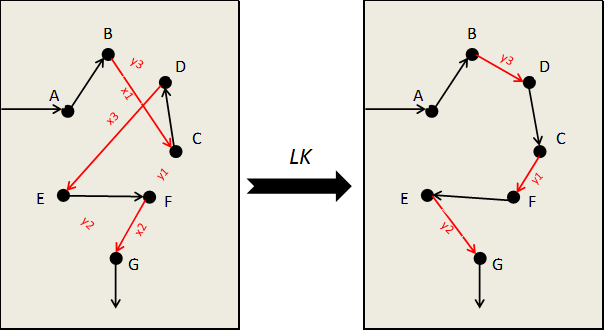
La première arête que l'on tente de supprimer est l'arête BC, notée x1. On cherche une arête de remplacement notée y1 partant de C parmi les plus proches voisins (dans notre exemple les quatre plus proches) et n'appartenant pas au tracé. Les choix possibles sont CF, CE, CA, CG. Toutes ces possibilités seront testées, c'est ce qu'on appelle un arbre de recherche.
Quand ce sera au tour de CF, une deuxième arête du tracé partant de F sera supprimée, notée x2. Il n'y a que deux possibilités, FG et FE. Si FG est analysée, comme pour y1, on essayera toutes les possibilités partant de G pour tester y2. Si y2 est GE, on recherche x3 partant de E, qui sera soit EF soit ED. Et si x3 est ED, alors y3 ne peut être que DB pour former un cycle réalisable.
En arrêtant l'algorithme à y2 nous obtenons une amélioration « 2-opt » et à y3 une amélioration « 3-opt », ainsi de suite. Évidemment, plus le nombre de voisins est grand, plus l'algorithme sera efficace, mais les temps de traitement augmenteront.
Ces améliorations, « 2-opt », « 3-opt », ou « LK », viendront s'ajouter à nos deux autres améliorations.
Nous pouvons désormais nous confronter à un parcours plus complexe.
VI. Le défi des 250 villes▲
Sur Internet j'ai découvert l'existence du « défi des 250 villes » : http://labo.algo.free.fr/defi250/defi_des_250_villes.html.
Une parenthèse : passer de 45 villes à 250, à première vue ça n'a pas l'air compliqué : 250/45 c'est 5,5 fois plus.
Seulement, malgré les améliorations que nous avons étudiées, le nombre de calculs à effectuer croît beaucoup plus rapidement que le volume des données en entrée. À cela s'ajoutent des traitements basés sur des tirages aléatoires qui rendent le calcul de l'ordre de croissance très difficile à effectuer. Retenez simplement que d'après mon expérience, pour passer de 45 villes à 250 villes, les temps de traitement seront 30 fois plus longs.
Pour vous faire une idée, imaginez une hôtesse d'accueil occupée qui vous dit « je suis à vous dans 5 minutes », c'est rassurant, vous patientez, surtout si elle est jolie. Mais si elle vous dit « merci de patienter une demi-heure », ce n'est pas pareil !
Oublions cette hôtesse et revenons au défi des 250 villes. L'avantage avec ce défi, c'est que la distance optimale à trouver est connue, 11,8092, ce qui permet d'évaluer l'efficacité de notre algorithme.
Après avoir téléchargé les coordonnées des points, j'ai lancé le calcul du parcours de base avant améliorations, ou cycle primaire :
|
|
Certains tracés se croisent. Comme vu précédemment, nous utiliserons l'amélioration « 2-opt » pour supprimer ces croisements. |

Après quelques secondes de traitement en utilisant un niveau 7 à la méthode naïve et au déplacement d'arêtes, puis en utilisant l'amélioration « 2-opt », j'obtiens un tracé d'une distance de 12,2285 soit 3,6 % de plus que le chemin optimal.
Ne disposant pas d'un super calculateur, je ne peux pas augmenter significativement les niveaux d'analyse sans faire exploser les temps de traitement.
De plus, ce tableau comparatif montre que ce n'est pas forcement la bonne approche :
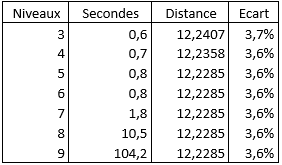
C'est l'impasse. Que faire ?
Puisque les quatre points de base du parcours, les points cardinaux, ont mené à ce résultat, il faudrait relancer le traitement, mais cette fois en prenant d'autres points de base.
Mais quels points prendre ? Et pourquoi se limiter à seulement quatre points ?
Je suis parti du principe que le parcours trouvé était une bonne base et que le parcours optimal devait grosso modo ressembler à celui-ci puis qu'il n'y a que quelques pourcentages d'écart. Il peut donc être utilisé pour le nouveau tracé de base en choisissant aléatoirement quelques points sur ce tracé, par exemple 30 % des points.
Cependant ces points risquent d'être dispersés sur le cycle et donc de générer des croisements. Il faudra ici utiliser la méthode de décroisement « 2-opt » dont nous avons parlé.
Les points restants seront ajoutés au tracé de façon à minimiser le parcours comme nous l'avons fait précédemment, par la méthode de l'insertion de moindre coût.
Il est même possible de générer plusieurs cycles primaires et de retenir celui qui a la distance minimale, c'est-à-dire celui qui est le plus prometteur.
C'est sur ce tracé prometteur que seront appliquées les améliorations.
Lorsqu'un parcours plus court que le premier est trouvé, ce nouveau tracé sert alors de tracé de base.
Mais pour éviter de tomber dans un « minima local » (un trajet constamment sélectionné, car il semble le plus prometteur, mais qui en réalité ne donnera jamais le trajet optimal), de temps en temps les points sont choisis aléatoirement sur le premier tracé de base constitué d'après les quatre points cardinaux.
Puis on recommence, jusqu'à épuisement du temps que nous souhaitons consacrer à cet exercice.
Avec un peu de chance, et de patience, on finit par trouver un parcours proche de l'optimal.
VII. Obtenir un meilleur tracé prometteur▲
C'est sur le tracé prometteur que sont appliquées les améliorations. D'où son importance.
La méthode que nous avons étudiée consiste à retenir le meilleur cycle primaire d'une série d'essais aléatoires. Ces essais sont basés :
- soit sur le meilleur cycle connu afin d'optimiser les chances de l'améliorer ;
- ou inversement, sur le tout premier cycle calculé, ceci afin d'éviter de tomber dans un minima local.
En effet, le plus grand danger est de se focaliser sur un cycle qui semble prometteur, mais qui n'aboutira à rien d'intéressant. Pour l'éviter, il faut élargir le champ de recherche (en faisant une plus grande place au hasard), mais pas trop, sans quoi vos chances de trouver un meilleur trajet diminuent.
Sacré dilemme.
En transposant cette situation à un marcheur perdu dans la forêt qui cherche la sortie, cela consisterait à tester au hasard des sentiers. En revenant de temps en temps à la meilleure position connue.
Pour une plus grande efficacité, une solution est d'avoir plusieurs marcheurs, qui font chacun de leur côté ces essais aléatoires, mais qui communiquent entre eux de temps en temps : alors tous les marcheurs repartent de la meilleure solution trouvée parmi l'ensemble des meilleures solutions des marcheurs.
Puis chacun teste à nouveau des sentiers de son côté. Ainsi de suite.
Cela permet de limiter le risque, sans le supprimer, de tomber dans un minima local, tout en favorisant un trajet prometteur.
Et pour éviter que nos marcheurs prennent les mêmes chemins, il est possible de mémoriser les chemins déjà testés, et leur interdire de suivre l'un de ces chemins dits « Tabou ». Cela force les marcheurs à explorer de nouvelles solutions qui ne sont pas a priori les plus prometteuses.
Une méthode pour ne pas rester bloqué dans un minima local (que j'ai retenue même si elle est radicale) est de repartir à zéro lorsqu'on atteint un nombre déterminé de chemins testés sans améliorer la meilleure solution trouvée.
Bien sûr, plus vous utilisez de marcheurs et plus les temps de traitement sont longs, mais vos chances de trouver un bon tracé prometteur sont meilleures. Finalement vous gagnez du temps.
Au défi des 250 villes, avec 10 marcheurs, souvent on passe sous les 1 % en moins de 10 minutes et 0,3 % est atteint en moins d'une heure.
Autre astuce : partant du principe que le premier parcours calculé est généralement entre 3 % et 5 % du parcours optimal, il est donc possible d'estimer la distance à environ 1 % ou 2 % du parcours optimal, et appliquer des paramètres différents quand le meilleur trajet trouvé est inférieur à cette distance. Ici tout est possible, par exemple : changer le nombre de marcheurs, changer la fréquence de communication entre les marcheurs, changer le taux des points à prendre aléatoirement sur le cycle de base, ou le nombre d'essais aléatoires…
Vous constatez que cet algorithme fait largement appel au hasard. C'est aussi le cas des algorithmes évolutionnaires.
VIII. Les Algorithmes évolutionnaires▲
Les algorithmes évolutionnaires s'inspirent de la biologie, de ses mutations génétiques aléatoires et de la sélection naturelle, qui permettent à une espèce de s'adapter au mieux à son environnement au fil des générations, d'où leur nom.
Leur objectif est de fournir une solution approchée à un problème d'optimisation en faisant évoluer une population et en retenant les meilleurs individus.
Les algorithmes génétiques sont les plus connus de la famille des algorithmes évolutionnaires.
Vous trouverez sur « developpez.com » un article de « khayyam90 » qui aborde ce sujet dans cette documentation : « https://khayyam.developpez.com/articles/algo/genetic/ ».
Ou sur Internet, par exemple : « https://perso.ensta-paris.fr/~kielbasi/docs/SIM202/projets/vdc.pdf ».
Le principe est assez facile à comprendre et à appliquer au problème du voyageur de commerce : un gène est une ville, un individu est un parcours, une population est un ensemble de parcours.
L'initialisation de l'algorithme génétique consiste à générer plusieurs parcours au hasard.
Puis on fait une boucle qui comporte trois phases.
La première phase consiste à générer de nouveaux parcours, en utilisant des règles inspirées de la biologie. Deux exemples parmi les nombreuses possibilités qui existent :
- par hybridation (cross-over en anglais) : on choisit au hasard un parcours dans l'ensemble des parcours mémorisés, on coupe ce parcours à une ville au hasard, on complète le parcours par les villes d'un autre parcours (en évitant qu'une ville soit reprise deux fois) ;
- par mutation : on échange au hasard des villes d'un parcours avec les villes d'un autre parcours.
Une fois cette phase appliquée à l'ensemble des parcours, nous disposons d'une nouvelle population qui a hérité des gènes de la population précédente.
La phase suivante consiste à évaluer les individus de cette population, c'est-à-dire dans notre cas, à calculer la distance des parcours. Pour gagner du temps de traitement, on peut appliquer nos améliorations non pas à l'ensemble des parcours, mais uniquement aux 10 % les plus prometteurs.
La dernière phase consiste à sélectionner les meilleurs individus de cette population (les plus courts chemins). Ici aussi tout est possible, par exemple : ne retenir que les 80 % meilleurs de la nouvelle population (les enfants), puis compléter la population en ajoutant au hasard des parcours de l'ancienne population (les parents), de façon à conserver un patrimoine de gènes.
La boucle n'est interrompue que lorsqu'une condition de sortie est remplie.
Pour sortir d'un minima local, lorsqu'un nombre déterminé de passages infructueux est atteint, une nouvelle initialisation est relancée, basée sur le meilleur résultat connu ou bien sur le pur hasard.
D'après ce que j'ai lu, il n'existe pas de règle précise concernant le choix des critères pour générer une nouvelle population ou pour sélectionner des individus. Avec mes réglages, je n'ai pas réussi à améliorer mon résultat au défi des 250 villes, mais nous allons voir dans les pages qui suivent que cet algorithme génétique peut nous rendre service.
IX. La solution au défi des 250 villes▲
Malgré de nombreuses tentatives avec l'algorithme que j'appelle « classique » et ses améliorations méthode naïve, déplacement des arêtes, 2-opt, 3-opt, LK) je n'ai jamais été capable de trouver la solution optimale au défi des 250 villes, 11,8092, et je suis resté bloqué à 0,2 %.
J'ai toutefois trouvé une parade…
Je suis parti de mon meilleur parcours, 11,8290, et j'ai lancé l'algorithme génétique, présenté ci-avant, avec un nombre de passages infructueux limité à 7 pour recentrer plus souvent les tests sur le meilleur chemin connu. Et après 12 heures de traitements et un peu de chance, l'algorithme génétique affiné par les améliorations, a trouvé un chemin à 11,8093214270636 soit 0,001 % de l'optimal.
J'ai comparé le tracé (en rouge) avec celui du site Internet (en bleu) :
|
|
Les deux tracés correspondent, l'écart de 0,001 % doit provenir des arrondis de calcul dans les distances entre les points. |
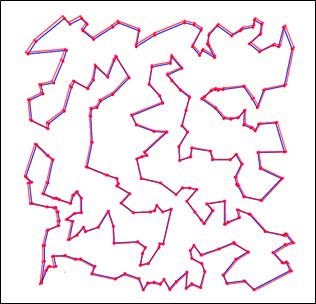
J'en déduis que, si l'algorithme génétique n'est pas aussi rapide que l'algorithme classique pour obtenir une solution approchée, il reste un bon outil pour finaliser la solution, grâce à sa faculté de générer des mutations qui peuvent être favorables.
D'où l'idée qui m'est venue de mixer ces deux algorithmes.
Le principe est le suivant : lorsque l'algorithme classique reste bloqué dans un minima local (la meilleure solution trouvée n'évolue plus) au lieu de repartir à zéro, l'algorithme génétique est utilisé avec une population initialisée en se basant aléatoirement sur le cycle premier et sur le meilleur cycle connu.
Et quand l'algorithme génétique sera bloqué à son tour, l'algorithme classique prendra la relève.
Cette méthode m'a permis de résoudre le défi des 380 villes (que vous trouverez dans le fichier de travail en annexe) en deux heures et avec un peu de chance.
Sources : http://www.math.uwaterloo.ca/tsp/vlsi/bcl380.tsp.
Voyons maintenant comment résoudre un cas plus concret.
X. Utiliser des distances réelles entre deux villes▲
Jusqu'à présent nous avons étudié des cas où la distance entre deux points, ou deux villes, était calculée d'après leurs coordonnées graphiques. Ces distances sont mémorisées dans une matrice, MatriceP(0 To n, 0 To n), pour accélérer les traitements.
C'est satisfaisant si vous faites de la recherche fondamentale, mais dans la réalité, si on reprend notre carte de France, rien ne prouve que le tracé obtenu (calculé sur les coordonnées graphiques des points) soit idéal.
|
|
Le survol de la mer entre Perros-Guirec et Cherbourg peut laisser perplexe sur ce trajet optimisé du tour de France en 45 villes. |
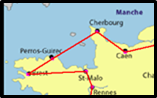
Si vous travaillez sur des cas concrets, il sera préférable de renseigner la variable MatriceP(0 To n, 0 To n) avec des valeurs réelles. Par exemple Google Maps donne le temps de trajet entre deux villes.
Il suffit alors de renseigner un tableau, dont voici un extrait, qui alimentera la matrice MatriceP() :
|
|
Les 45 villes du problème sont placées en colonne A, et transposées sur la ligne 1. Les valeurs indiquées ici représentent la durée du trajet entre deux villes, exprimée en minutes, « dans des conditions normales de circulation », d'après Google Maps. |
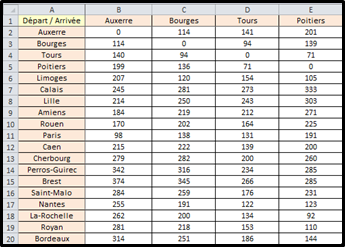
Le tableau comporte donc 45 lignes et 45 colonnes, soit 45 x 44 = 1980 trajets calculés.
Car Auxerre-Tours (141 min) ne donne la même durée que Tours-Auxerre (140 min).
Renseigner ce tableau à la main risque d'être fastidieux.
L'idée est bien sûr d'utiliser le VBA pour interroger Google Maps et en extraire la durée calculée.
Vous trouverez des documentations très bien faites pour apprendre à interagir avec un site Internet : « Interaction avec Internet Explorer via VBA Excel », de Qwazerty, à cette adresse : « https://qwazerty.developpez.com/tutoriels/vba/ie-et-vba-excel/ » et « VBA et développement Web », de Thierry Gasperment, à cette adresse : « https://arkham46.developpez.com/articles/office/officeweb/ »
Je me suis contenté d'écrire à la va-vite un code très simple qui permet d'ouvrir Google Maps en passant en arguments la ville de départ et la ville d'arrivée (vous pouvez aussi passer une adresse complète avec numéro et nom de rue). Le site se charge de calculer la durée du trajet. Il reste juste à parcourir le « corps du document » à la recherche de l'information désirée (voir les fonctions du module « Google_Maps », pensez à ajouter les bibliothèques « Microsoft HTML Object Library » et « Microsoft Internet Controls » à votre projet).
Et en trois heures le tableau est rempli automatiquement.
À partir de ces nouvelles données, le traitement est relancé pour voir si le résultat est identique :
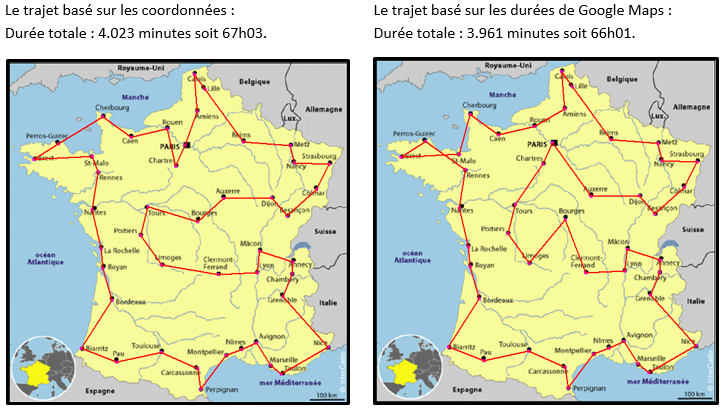
Il y a donc environ une heure de moins de trajet routier entre ces deux parcours.
Suivant l'objectif désiré, vous pouvez aussi faire vos calculs en évitant les péages, ou en utilisant les kilomètres au lieu des temps de trajets.
Vous obtiendrez sûrement un trajet différent.
Maintenant que vous connaissez tout des possibilités de la fonction PVDC et de la façon dont elle travaille, il est temps de vous expliquer comment l'intégrer dans vos applications.
XI. Utiliser la fonction PVDC▲
Je vais vous épargner la lecture des 3000 lignes du code source des diverses procédures utilisées.
Ceux que cela intéresse trouveront leur bonheur dans les modules du fichier EXCEL joint.
Pour les débutants en VBA, la lecture du tome 1 sera une étape obligatoire pour acquérir le niveau requis.
Quant au tome 2, il vous permettra de comprendre la programmation en mode graphique utilisée pour dessiner les parcours dans un formulaire.
Je pense surtout aux autres, qui souhaitent une fonction facile à appeler dans leurs applications. C'est pourquoi j'ai développé la fonction publique PVDC qui retourne la meilleure combinaison calculée.
Cette fonction possède les arguments suivants, dont seul le premier est obligatoire. Et la lecture des pages précédentes vous a permis d'en comprendre l'utilité :
- TabDonnées() As Double : c'est la liste des coordonnées des points du cycle. Variable à deux dimensions, dimension 0 pour les abscisses (x), et dimension 1 pour les ordonnées (y) ;
- TestsMaxi (0 par défaut) : c'est le nombre maximum de tests à effectuer pour la recherche du meilleur résultat. Chaque test peut avoir plusieurs cycles primaires de générés (voir NbTestsCyclesPrimaires). Quand ce nombre est atteint, s'il est différent de zéro, le traitement se termine automatiquement ;
- DuréeMaxi (0 par défaut) : c'est le nombre maximal de minutes à consacrer au traitement. Passé ce délai, s'il est différent de zéro, le traitement se termine automatiquement ;
- Nb_Indices As Byte (6 par défaut) : c'est le niveau d'analyse pour la méthode naïve ;
- NbTestsOptimRaccourcis (10 par défaut) : c'est le niveau d'analyse du déplacement d'arêtes ;
- NiveauOptim (Optim2Opt_LPA par défaut) : indique s'il faut faire une amélioration « 2-opt » limitée aux points en aval (Optim2Opt_LPA) , ou complète (Optim2Opt), ou « 3-opt » limitée aux points en aval (Optim3Opt_LPA), ou inspirée de Lin-Kernighan (Optim_LK) ou aucune (Optim_Désactivé). Voir l'annexe 1 pour d'autres informations ;
- NbMarcheurs (10 par défaut) : c'est le nombre de marcheurs à lancer à la recherche de la meilleure solution. Si 0 est indiqué, l'algorithme génétique sera appliqué à la place de l'algorithme classique.
Un chiffre négatif indique qu'il faudra basculer sur l'algorithme génétique si la situation est bloquée au lieu de repartir à zéro, et revenir à l'algorithme classique quand l'algorithme génétique sera bloqué à son tour ;
- NbTestsCyclesPrimaires (10 par défaut) : c'est le nombre de cycles primaires à générer à chaque test pour chacun des marcheurs ;
- NbPassagesInfructueux (10 par défaut) : nombre de passages infructueux avant de repartir à zéro, ou de basculer entre les algorithmes classiques et génétiques ;
- DistanceOptimale As Double (0 par défaut) : si la distance optimale est connue, cela permet d'afficher l'écart en pourcentage entre le meilleur cycle calculé par l'algorithme et cette distance optimale ;
- MyForm As Object (vide par défaut) : c'est le nom du formulaire à utiliser pour dessiner les cycles calculés. Les points du cycle sont automatiquement mis à l'échelle du formulaire. À la fin du traitement, une image du formulaire, avec le dessin du meilleur cycle, est automatiquement sauvegardée dans le répertoire de l'application sous le nom de « CopieEnBMP.BMP » ;
- MatriceDistances As Variant (vide par défaut) : c'est la matrice des distances à utiliser, à la place du calcul basé sur les coordonnées graphiques des points. Variable à deux dimensions, dimension 0 pour les x, et dimension 1 pour les y.
La fonction retourne la liste des points du meilleur cycle calculé (dans une variable à une dimension) dans les indices 0 à n. Cette variable est de type Double, car son indice -1 contient la distance totale calculée.
L'indice 0 de cette liste correspond au premier point de la liste d'origine, car ce premier point est considéré comme le point de départ du cycle, et aussi le point d'arrivée.
À tout moment le traitement peut être interrompu en maintenant les touches [Majuscule] + [Fin] enfoncées.
Le module contient aussi des constantes pour permettre aux plus courageux de se lancer dans l'aventure :
- AfficheOrigine As Boolean : affiche dans le formulaire le numéro d'origine du point ;
- AfficheOrdre As Boolean : affiche dans le formulaire le numéro d'ordre du point dans le cycle ;
- TauxAléatoire As Double = 0.3 : taux pour prendre des points au hasard dans le cycle de base ;
- EnregistreClasseur As Boolean : enregistre le classeur quand il y a un nouveau minimum, et sauvegarde le meilleur cycle sur la feuille « Mini » ;
- AfficheClasseur As Boolean : affiche dans le classeur les résultats intermédiaires ;
- AfficheEnPermanance As Boolean : affiche dans le coin supérieur gauche de l'écran la progression du traitement - nombre de tests, durée écoulée, distance du meilleur cycle, ou bien taux par rapport au cycle optimal connu. Cela vous permet de suivre d'un œil le traitement tout en travaillant sur une autre application ;
- TaillePopulation As Integer = 300 : c'est la taille de la population pour l'algorithme génétique ;
- VérifieSiCheminsDéjàTestés As Boolean : indique s'il faut ou non mémoriser les chemins déjà parcourus par les marcheurs afin de favoriser de nouveaux chemins qui ne sont pas favorables ;
- ChargeDonnéesDepuisHI As Boolean : indique s'il faut charger le cycle de base depuis le meilleur cycle connu, en colonnes H et I ;
- NbVLK As Integer = 5 : c'est le nombre de voisins analysés par l'algorithme inspiré de Lin-kernighan.
Voici un exemple d'appel, pour suivre l'avancée des traitements dans la barre d'état :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
'---------------------------------------------------------------------------------------
Sub PVDC_250()
'---------------------------------------------------------------------------------------
Dim y As Integer, n As Integer, TabDonnées() As Double, CyclePVDC() As Double
y = 2
' Chargement des données sur la feuille de calcul (qui sont en colonnes A et B) :
While Cells(y, 1) <> ""
ReDim Preserve TabDonnées(0 To 1, 0 To n)
TabDonnées(0, n) = Cells(y, 1)
TabDonnées(1, n) = Cells(y, 2)
y = y + 1: n = n + 1
Wend
' Lance le traitement du calcul du chemin le plus court (sur seulement 20 tests):
CyclePVDC = PVDC(TabDonnées(), TestsMaxi:=20, DuréeMaxi:=0, _
Nb_Indices:=6, NbTestsOptimRaccourcis:=6, _
NiveauOptim:=Optim2Opt_LPA, _
NbMarcheurs:=10, NbTestsCyclesPrimaires:=10)
' Affiche le meilleur cycle trouvé :
MsgBox "Distance du meilleur cycle : " & Format(CyclePVDC(-1), "0.0000")
End Sub
Voici un exemple d'appel, pour exécuter la fonction PVDC sur l'exemple des 45 villes en utilisant les temps de trajets dans la feuille « Trajets_France ». Les cycles calculés sont dessinés dans le formulaire UserForm1 qui contient l'image de la carte de France (celle utilisée dans cette documentation).
Les coordonnées des villes sont en colonnes « A » et « B » , et leur nom est contenu en colonne « C ».
À la fin du traitement il est possible d'afficher (ou non) le cycle calculé en colonnes G, H, I :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
'---------------------------------------------------------------------------------------
Sub PVDC_France()
'---------------------------------------------------------------------------------------
Dim y As Integer, x As Integer, n As Integer, i As Integer
Dim TabDonnées() As Double, CyclePVDC() As Double
Dim TabLibellés() As String
Dim MatriceDistances() As Double
y = 2
' Chargement des données sur la feuille de calcul:
While Cells(y, 1) <> ""
ReDim Preserve TabDonnées(0 To 1, 0 To n) ' Mémorise les coordonnées graphiques.
ReDim Preserve TabLibellés(0 To n) ' Mémorise le nom des villes.
TabDonnées(0, n) = Cells(y, 1) ' Colonne A pour les coordonnées x.
TabDonnées(1, n) = Cells(y, 2) ' Colonne B pour les coordonnées y.
TabLibellés(n) = Cells(y, 3) ' Colonne C pour les noms des villes.
y = y + 1: n = n + 1
Wend
' Chargement des distances réelles entre deux villes d'après le tableau des trajets des villes :
n = n - 1 ' n contient maintenant le nombre de villes.
ReDim MatriceDistances(0 To n, 0 To n)
y = 2
While Sheets("Trajets_France").Cells(y, 1) <> ""
x = 2
While Sheets("Trajets_France").Cells(1, x) <> ""
MatriceDistances(x - 2, y - 2) = Sheets("Trajets_France").Cells(y, x)
x = x + 1
Wend
y = y + 1
Wend
' Lance le traitement du calcul du chemin le plus court (sur seulement 11 tests):
CyclePVDC = PVDC(TabDonnées(), TestsMaxi:=11, DuréeMaxi:=0, _
Nb_Indices:=6, NbTestsOptimRaccourcis:=10, _
NiveauOptim:=Optim2Opt, _
NbMarcheurs:=10, NbTestsCyclesPrimaires:=10, _
MyForm:=UserForm1, MatriceDistances:=MatriceDistances())
' Boîte d'information pour savoir s'il faut afficher dans le classeur le meilleur cycle calculé :
If MsgBox("Distance du meilleur cycle : " & Format(CyclePVDC(-1), "0.0000"), _
vbYesNo, "Enregistrer le tracé ?") = vbYes Then
Cells(1, 11) = CyclePVDC(-1) ' Cellule " K1 " = Durée calculée.
For i = 0 To UBound(CyclePVDC) ' Boucle sur le cycle.
Cells(i + 2, 7) = TabLibellés(CyclePVDC(i)) ' Colonne G = Nom de la ville.
Cells(i + 2, 8) = TabDonnées(0, CyclePVDC(i)) ' Colonne H = Coordonnée x.
Cells(i + 2, 9) = TabDonnées(1, CyclePVDC(i)) ' Colonne I = Coordonnée y.
Next i
Cells(i + 2, 7) = TabLibellés(CyclePVDC(0)) ' Colonne G = Reprend la ville de départ.
Cells(i + 2, 8) = TabDonnées(0, CyclePVDC(0)) ' Colonne H = Reprend la Coordonnée x de départ.
Cells(i + 2, 9) = TabDonnées(1, CyclePVDC(0)) ' Colonne I = Reprend la Coordonnée y de départ.
End If
End Sub
Ce qui donne cette restitution sur la feuille de calcul :
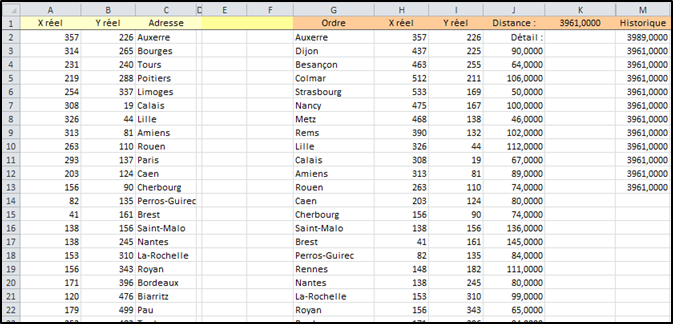
Les distances de la colonne « J » sont issues d'une formule d'EXCEL, qui va chercher les données dans le tableau des durées des trajets entre deux villes de la feuille « Trajets_France »
J3 : =INDEX(Trajets_France!A:AT;EQUIV(G3;Trajets_France!$1:$1;0);EQUIV(G2;Trajets_France!$A:$A;0))XII. Pseudo-code simplifié de la fonction PVDC▲
Initialisation des 4 premiers points du cycle primaire, d'après les 4 points cardinaux.
Ajout des autres points au cycle primaire, d'après la méthode de l'insertion de moindre coût.
Suppression des croisements.
Amélioration du cycle.
Prendre le cycle amélioré comme référence pour le cycle des marcheurs (cycle premier).
Initialisation de la population de l'algorithme génétique en se basant sur ce cycle premier.
Tant qu'une condition de sortie n'est pas remplie :
S'il faut utiliser l'algorithme génétique :
Hybridation de la population, retenir 80 % des meilleurs enfants et compléter par des parents pris au hasard.
Amélioration des 10 % meilleurs individus.
Si une nouvelle meilleure distance est trouvée :
Tester une amélioration 3-opt et LK.
Mémoriser cette nouvelle meilleure distance y compris pour les autres marcheurs.
S'il faut utiliser l'algorithme classique :
Pour chaque marcheur :
Tous les 2 passages, prendre comme base le meilleur cycle du marcheur.
Tous les 17 passages, prendre comme base le meilleur cycle de l'ensemble des marcheurs.
Pour le nombre de cycles aléatoires à créer pour le marcheur :
Création d'un nouveau cycle en prenant des points au hasard.
Suppression des croisements.
Ajout des autres points suivant la méthode de l'insertion de moindre coût.
Suppression des croisements.
Retenir le meilleur cycle aléatoire qui n'a pas déjà été testé par un des marcheurs.
Améliorer ce cycle.
Pour chaque marcheur :
Si une nouvelle meilleure distance est trouvée, alors tester une amélioration 3-opt et LK.
Afficher les informations sur la progression du traitement dans la barre d'état.
Si le nombre de passages infructueux est atteint :
S'il faut basculer entre l'algorithme classique et l'algorithme génétique alors, déclencher la bascule.
Si l'algorithme classique est utilisé alors,
soit repartir du cycle premier pour tous les marcheurs et effacer la mémoire des parcours déjà testés (cas où il n'y a pas de bascule),
soit repartir avec la moitié des marcheurs initialisés avec les meilleurs individus connus.
Si l'algorithme génétique est utilisé alors,
initialiser la population en se basant aléatoirement sur le cycle premier et sur le meilleur cycle connu.
Fin de la boucle.XIII. Conclusion▲
Les tenants du verre à moitié vide seront frustrés de ne pas obtenir la meilleure solution à chaque essai.
Pour les optimistes le verre sera à moitié plein, et flirter avec la solution optimale est une grande réussite. Et puis la fonction première d'un algorithme d'approximation est de donner un résultat approximatif.
L'algorithme présenté dans ce mémento est certes simple à comprendre, mais il est loin d'être parfait, car à partir de 500 points les temps de traitements deviennent longs et à partir du millier, ils sont « déraisonnables ». Cet effet d'échelle est appelé par les spécialistes « la malédiction de la dimension » (Curse of dimensionality).
Alors si vous connaissez une méthode d'amélioration efficace, et facilement implémentable en VBA, n'hésitez pas à nous en faire profiter.
Par exemple, si vous avez des informations sur l'algorithme de Lin et Kernighan, je suis preneur.
Vous trouverez d'autres parcours sur ce site : http://www.math.uwaterloo.ca/tsp/data/
(attention, ne vous fiez pas aux distances optimales indiquées, elles sont à recalculer d'après les parcours optimaux donnés).
Ou sur : http://www.cs.princeton.edu/courses/archive/spr15/cos126/assignments/tsp.html
Ou sur : http://elib.zib.de/pub/mp-testdata/tsp/tsplib/tsp/
Ou en recherchant sur Internet avec « data traveling salesman problem ».
Sans oublier la référence incontournable, le logiciel Concorde, pour les forts en maths : http://www.math.uwaterloo.ca/tsp/concorde/index.html.
Le problème du voyageur de commerce est un sujet d'étude qui a des applications très concrètes : programmation d'un robot dans une chaîne de montage qui doit faire des soudures sur des pièces, planification du parcours d'un drone de surveillance…
Ou comme indiqué dans Wikipédia « On peut citer des applications plus surprenantes, par exemple, en biologie, le problème aide au séquençage du génome pour relier des petits fragments en des chaînes plus grandes ».
Ce mémento suscitera peut-être des vocations…
Laurent OTT.
2017.
Annexe 1 : Un peu de vocabulaire▲
Si ce sujet vous intéresse et que vous désirez en apprendre plus, vous trouverez sur Internet des documentations qui emploient un vocabulaire qui peut déstabiliser les néophytes. D'où l'idée de présenter ci-dessous quelques clés destinées à ceux qui ne sont pas familiers avec les termes utilisés dans ces articles.
Un Graph : c'est la représentation du parcours à optimiser, c'est-à-dire l'ensemble des villes à visiter. Les villes sont les sommets du graph, le trajet entre deux villes est une arête souvent notée (i, j).
Un cycle Hamiltonien : le parcours du voyageur de commerce est dit cycle Hamiltonien, car le voyageur passe par toutes les villes, sans passer deux fois dans la même ville, puis retourne à son point de départ.
Ce cycle est dit symétrique s'il est possible de faire la tournée dans les deux sens, c'est ce que nous faisons. Dans ce cas le problème du voyageur de commerce est appelé TSP (Traveling Salesman Problem).
Pour trouver le cycle minimal, nous calculons la distance du cycle, ce qui est appelé une fonction d'évaluation. Car c'est uniquement la distance globale qui nous intéresse. Mais il faut parfois inclure d'autres contraintes, comme le temps de trajet en tenant compte des embouteillages, ou la pause nécessaire pour déjeuner ou dormir, le problème est alors appelé TSPTW (Traveling Salesman Problem With Time Windows).
Il existe deux grandes familles d'algorithmes pour résoudre le problème du voyageur de commerce :
Ceux qui donnent un résultat exact, ceux qui donnent un résultat approché. Pour ces derniers, on parle de méthode d'approximation, ou de méthode heuristique.
Les algorithmes qui, pour un problème donné, donnent toujours le même résultat avec le même temps d'exécution sont dits déterministes. Inversement, les algorithmes non déterministes font appel au hasard, on parle alors d'algorithme probalistique, aléatoire ou stochastique.
Une fois l'algorithme heuristique appliqué, il faut améliorer le trajet calculé. C'est ce qu'on appelle les optimisations locales. Diverses variantes existent :
- faire l'amélioration dès qu'elle est rencontrée (voir dans le code source la fonction TROIS_OPT_LPA) ;
- évaluer toutes les améliorations possibles et ne faire que la meilleure puis recommencer la boucle d'évaluation (voir la fonction DEUX_OPT_LPA) ;
- mémoriser toutes les améliorations et faire les améliorations au hasard dans cette liste (voir la fonction DEUX_OPT).
Dans tous ces cas, il est possible de reprendre ou non l'évaluation du cycle depuis le début (ou depuis le premier point modifié) à la recherche de nouvelles optimisations locales.
Autre possibilité, que j'ai retenue : faire des améliorations rapides, de type « Optim2Opt_LPA », mais lorsqu'un nouveau meilleur cycle est trouvé, lui appliquer automatiquement une amélioration plus complexe « Optim3Opt_LPA » et "Optim_LK.
Dans une amélioration on distingue Swap Move qui échange deux villes consécutives de Exchange Move qui échange deux villes quelconques, et Insertion Move qui supprime une ville puis l'insère ailleurs.
Annexe 2 : Les fichiers EXCEL joints▲
PVDC.xlsm : regroupe les modules qu'il faudra intégrer à vos applications.
PVDC.xls : est la version compatible pour EXCEL 97.
PVDC_Exemples.xlsm : est la version de travail qui contient en plus des exemples de parcours et le détail de leur résolution.
XIV. Remerciements▲
Je tiens à remercier Pierre Fauconnier, dourouc05, Lolo78 pour la relecture technique et leurs corrections des erreurs que j'avais écrites, Winjerome, et Siguillaume pour les corrections sur la mise au gabarit de Developpez.com, et Claude Leloup pour la relecture orthographique.